This post is the third in a series developed to support the GDAT (Genealogical DNA Analysis Tool) Chromosome Analysis Group at the Society of Australian Genealogists (SAG). It does not replace the extensive user guide and help video tutorials already developed by the GDAT team. Members of the User Group should always consult those resources first.
You can access Parts 1 and 2 by clicking the links below, or the user guide for more specific information.

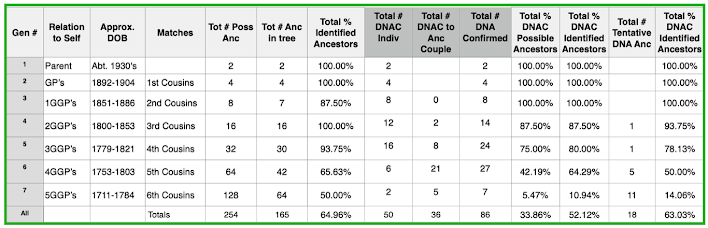
- identified all your ancestors out to at least the 2nd great grandparent level;
- identified DNA cousin matches up to 3rd cousins that confirm that your 2nd great grandparents (P1-8 and M1-8) are also your genetic ancestors. These relationships can be confirmed provided you and your match share the appropriate cMs for the predicted relationship. Ideally, as many as possible of these close matches should have their results on a chromosome analysis site to enable you to build on these confirmed relationships and 'walk back the segments' to more distant ancestors using GDAT;
- used your DNA results to identify any unknown ancestors closer than 2nd great grandparents using the total cMs approach, if traditional research techniques have previously been unsuccessful;
- identified DNA matches for all your lines, with shared ancestors back to each of the 8 sets of ancestral couples at the 2nd great grandparent level. If not, reconsider whether the ancestors you have identified are actually the right ones? This will not always be the case, there are many reasons why you might have no matches, but more often than not it may be an indicator that either your research is wrong or the parent of your ancestor may be someone completely different;
- extended your pedigree out as far as you can - the more complete your tree the greater your chance of success in finding connections with your DNA matches!

- Relative - views relevant to your DNA matches;
- Profile - views relevant to people whose DNA you are monitoring;
- MRCA - tools to assist your research.
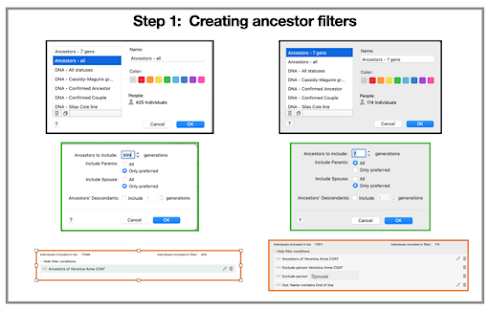
- F2 - Relative Ahnentafels. To maximise your productivity, it is best to load pedigree information for your matches via a 'bulk import' from a third party tool as DNAGedcom. The F2 function provides the ability to add pedigrees manually via GEDcom import, Pedigree Thief and One2Tree (Windows only), plus you can also update details on existing ahnentafels already loaded to GDAT. Don't forget you can also upload GEDcoms extracted from your own family history program if you have researched your relatives ancestry, or just fill in the blank page!

- F3 - Family comparisons. This screen compares genealogical information between the profile and matches, identifying any common surnames. Highlighting the surname gives more information about your ancestor, so you can compare them to your matches ancestor list. If no surnames show for your match but they have an ancestor list, go back to the F2 screen, choose Update, then 'set relative lists to Ahnentafel values' and the missing surnames should populate.

- F5 - Merging. There are two main pathways I use for merging duplicate profiles. If you identify them in the F7 chromosome browser, highlighting the matches then right clicking will lead you to the F5 page. Or you can access the same F5 page via the Relative Menu. To complete the merge you need to remember to have the relative information you want to keep on the right. Tick boxes on the left if you want to retain that information. Things to keep an eye out for when deciding which relative to choose are - where Ahnentafel value = true, segments or status of MRCA are already assigned or if there are research notes. Always back up before a merge, so you can revert the database if the merge does not behave how you expected. In the case of duplicates, select the 'same person' radio button, then merge. There is also an option to select 'other' - this option can be used for combining relative records for closely related relatives. Check the user guide for more information.

- F7 - Analysis Tools. When reviewing matches in the F7 chromosome browser, highlighting the matches then right clicking will bring up a menu. The compare ahnentafel groups option will identify any shared ancestror couple names between the highlighted matches. Similarly, the compare ahnentafel surnames will identify any shared surnames within the match group. This can assist in finding possible connections between your matches.

The MCRA menu has some great genealogical tools that enable you interrogate the database in different ways and can be very useful in finding more genealogical connections.
- Segment MRCA's - This tool identifies matches whose status has been set to MRCA and lists them under the name of the MRCA group allocated to individual segments. It provides a good summary of each of the 'family group' names you have listed in the profile ancestor list (F6) and all your confirmed matches;
- Groups associated with MRCA's -This tool aims to find you more possible connections to your MRCA. For each of your family groups, it lists the group names of your identified and confirmed relatives back to the shared ancestors. Often these can be names little known to you. Investigating matches with these surnames in their trees can often lead to other descendants from these same ancestor groups. Because the group name is the same however, it does not always mean they are the same people, you need to do the research to confirm or reject them.
- ICW profile group - This tool lists relatives who have the same group names in their tree as the profile person, but have not yet been given the status of MRCA. These require investigation and can lead to identifying more shared ancestors. Whilst many of those with common names or listed as Unknown or MNU can be misleading, if you regularly use the MRCA notes field, the process can often bring to light other matches you may have previously investigated that should be revisited.
- Region clusters - This tool lists places names in common with the profile and their matches. Group name formatting needs to be consistent so not all your places will be listed if your match describes the place name differently. Can be useful for identifying matches from particular localities of interest.
The GDAT database won't find every connection, at times you will need to do research on your matches trees to find your shared ancestors. Remember to add new surnames and additional pedigree information to your relatives pages to maximise the effectiveness of the genealogical tools.
* Make sure you first consult the extensive GDAT User Guide;
* Join the Facebook Group for GDAT and search the site to see if the question has been asked before. If not, ask the question there;
* SAG members can join the 'private' SAG GDAT User Group on Facebook for general collaboration between members.
* Back up regularly (under File);
* Use the available Help resources (under Help);
* If imports or views aren't behaving as you would expect, you probably need to adjust some of the defaults (under Preferences)
* Keep notes, one of the great features of GDAT is being able to easily pick up where you left off last time!
Finally....